
sam入门
工作介绍
基于分割大模型sam,通过微调等方法迁移到分割相关领域辅助模型训练。
相关文章
Segment Anything
原始SAM文章,给出了模型架构,训练方法。
价值:学习到SAM基本输入输出形式,方便调用。
代码:facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. (github.com)
SAM-Assisted Remote Sensing Imagery Semantic Segmentation with Object and Boundary Constraints
一个基于sam辅助训练的语义分割模型。SAM 仅限于生成没有类别信息的分割结果,提出了一种辅助训练方法。通过调用sam大模型的接口,辅助遥感变换检测类任务训练。
数据集:ISPRS Vaihingen 和 LoveDA Urban遥感语义分割
代码:sstary/SSRS (github.com)
价值:
通过sam模型获取到图片的对象(SGO)和边界(SGB),提出了提出了一种新颖的对象一致性损失,并在这项工作中进一步引入了边界保留损失。
方法:

主干网络使用Unetformer等主流分割方法,外加从sam导出的SGO与SGD进行损失计算。
冻结SAM的使用方法:
SAM使用方法:
SAM 提供了一组应用程序编程接口 (API),只需几行代码即可获得分段掩码。 API 中的不同提示支持不同的分割模式选项,例如全自动、边界框、点模式。
损失计算方法:
- 字母含义介绍:
$X$:输入图像
$P$:模型预测分割输出
$C$:需要分割的总类别数
$Y$:真实分割标签图
$Y{o}$:sam生成对象图(SGO)
$Y{b}$:sam生成边界图(SGB)
$M^{i}$:从SGO中对每一个对象提取得到的掩码
- $L_{seg}$分割损失计算方法:
- $L_{obj}$对象一致性损失计算方法:

对象特征:对象平均特征:其中G计算空间维度中所有像素的总和并重塑为其原始形状。
$N^i$是第$i$个对象中的点数
对象一致性损失计算:
MSE是均方误差 - $L_{obj}$边界保留损失计算:
合并边缘约束可以有效增强遥感任务中语义分割模型的性能
边界全部设置为0
计算方法为:$p_b$和$r_b$分别为边界的精读和召回率 - 总损失
SamLP A Customized Segment Anything Model for License Plate Detection
用sam定制的车牌检测模型
设计了一种低秩适应(LoRA)微调策略,将额外的参数注入到 SAM 中,并将 SAM 转移到 LP 检测任务中。
代码:Dinghaoxuan/SamLP (github.com)贡献:
- 将参数高效微调(PEFT)引入到SAM的传输中。具体来说,我们在我们提出的 SamLP 中提出了低秩适应 (LoRA) 调整策略,以使 SAM 适应 LP 检测数据集。LoRA:使SAM 最独特的能力(即位置提示)被抑制
- 可提示的(promptable)微调训练策略,及时车牌检测
- 少样本迁移能力
参数高效微调技术(PEFT): - 适配器调优Adapter tuning:在模型的每个层中插入小的、可训练的神经网络(称为 “adapters”),而不是调整模型的全部参数。
- 提示调优prompt tuning:在输入给模型的提示(prompt)中添加或优化一些 “tokens”,这些 “tokens” 被训练来改善模型的任务性能。
- LoRA调优: 对 Transformer 中每一层的可训练低秩分解矩阵进行微调,即添加较小的可训练矩阵,显着减少可训练参数的数量。

MaskDecoder的输出有:预测输出的掩码$\widehat{S}$,Iou分数Score,feature logits,各三个:pipeline:
具体而言,微调分为两个步骤:LoRA微调和promptable微调。首先,LoRA微调策略在SAM模型的图像编码器和掩码解码器的Transformer块中插入了一些LoRA层。这些LoRA层用于调整图像编码器以提取与车牌相关的特征,并使掩码解码器生成车牌分割掩码。在LoRA微调步骤中,由于输入仅为单个图像I,因此车牌的位置先验是未知的,因此没有提示编码器的信息,LoRA微调的输入提示为None。这意味着提示编码器没有适应车牌检测任务。为了保持SAM模型的可提示分割能力,设计了第二步,即可提示微调。在可提示微调中,来自LoRA微调的车牌分割结果被视为先验提示,用于引导可提示分割的训练。整个图像编码器及其LoRA层被冻结,只有提示编码器和掩码解码器中的LoRA层进行训练,以避免在图像嵌入中发生灾难性的遗忘,并加速可提示微调的训练过程。LoRA调优方法:
预训练语言模型的学习能力在将模型投影到低秩子空间时仍然有效。这意味着预训练模型具有较低的内在维度,在模型适应过程中参数的更新也具有较低的内在秩。
基础模型的预训练参数为$W_0 ∈ R^{d×k}$,其中d为输入特征维度,k为输出特征维度。$W_0$的优化方法: - A矩阵($A ∈ R^{r×k}$):这是一个低秩分解矩阵,其中r是低秩的大小,k是输出特征的维度。
- B矩阵($B ∈ R^{d×r}$):这也是一个低秩分解矩阵,其中r是低秩的大小,d是输入特征的维度。
输入特征 $x ∈ R^{n×d}$ (n 是扁平化输入特征 x 的序列长度)同时与 $W_0$ 和 $ΔW$ 相乘,然后将它们的输出按元素求和作为输出特征 $h ∈ R^{n×k}$:
在 LoRA 微调步骤中,输入图像 I 被馈送到具有 LoRA 层的图像编码器中以获得图像嵌入。然后,输入提示P为None,这意味着没有点、框或掩模输入到提示编码器。之后,None 的提示嵌入与掩码标记相结合,然后掩码解码器从图像编码器检索图像嵌入中的高响应区域以生成二进制分割掩码。最后计算Dice损失:可提示调优Promptable Fine-tuning
设计了一个迭代细化训练管道,将提示引入分割中。
Adapting Segment Anything Model for Change Detection in VHR Remote Sensing Images
采用sam进行 VHR(超高分辨) 遥感图像变化检测
为了使 FastSAM 专注于 RS 场景中的某些特定地面物体,提出了一个卷积适配器来聚合面向任务的变化信息。为了利用 SAM 特征固有的语义表示,引入了一个与任务无关的语义学习分支来对双时态 RSI 中的潜在语义进行建模。在本文中,我们的目标是利用 SAM 强大且通用的语义开发能力来提高 CD 的准确性并减少对大量训练样本的依赖。
代码:ggsDing/SAM-CD: Pytorch code of the SAM-CD (github.com)
贡献:
- SAM-CD 将 FastSAM(SAM 的高效变体)适应 RS 场景,并利用多时态 LCLU 信息来嵌入变化表示。
- 将与任务无关的潜在图像学习引入到 CD 框架中。利用 SAM 的通用语义表示功能,生成的模型能够对 RSI 中的底层 LCLU 分布进行建模,以提高变化检测的准确性。这是通过测量多时间特征之间语义表示的相似性来监督的。
SAM局限性:
在某些领域表现出明显的局限性,包括医学图像、制造场景和 RSI 。由于它们主要接受自然图像的训练,因此它们倾向于更多地关注前景物体,并且难以分割小且不规则的物体。在这项工作中,我们利用自适应来微调 SAM(FastSAM),以学习 VHR RSI 中的潜在语义。
典型的变化检测方法:
利用两个连体编码器来提取时间特征,然后使用共享解码器将它们嵌入到变化表示中。
字母解释:
$(x_1,x_2)$:时间图像对
$U()$:编码器网络
$V()$:解码器网络
$m$:二进制CD图
本文方法
我们期望通过比较底层语义特征可以更好地学习语义变化。通过视觉基础模型,现在可以在没有分类注释的情况下提取地面物体的语义。将视觉基础模型(VFM)作为视觉编码器,表示为$\widehat{U}()$,来提取通用语义特征(而不是时间差异)。得到预测CD图表示为:
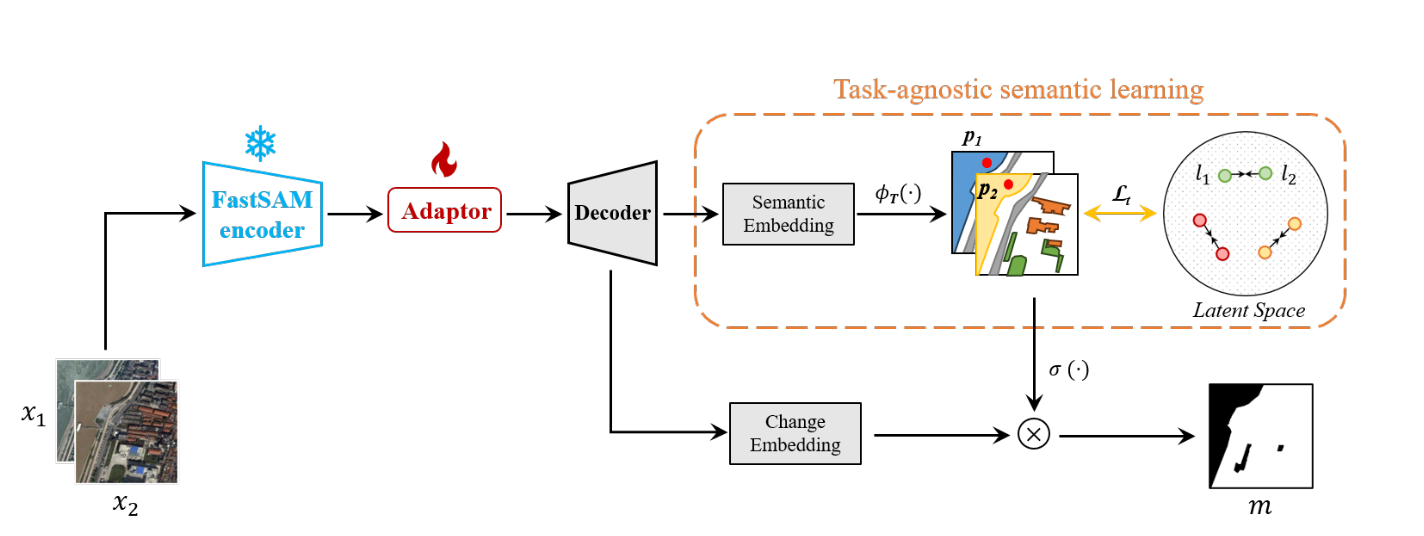
首先,我们利用 FastSAM 作为冻结编码器来利用视觉实体。为了更好地推广 RSI,引入了可训练的适配器来适应提取的特征。获得的多尺度 FastSAM 特征在类似 unet 的卷积解码器中进行融合和上采样。然后,除了嵌入变化表示的变化分支之外,我们还引入了一个额外的与任务无关的语义学习分支来对底层潜在语义进行建模。由此产生的 SAM-CD 是语义感知的,因此它可以更好地捕获 VHR RSI 中的对象变化。
FastSAM Adaptor
首先,我们将FastSAM在1/32、1/16、1/8和1/4的空间尺度上提取的特征进行聚合,表示为f1、f2、f3、f4。每个特征 fi 由相应的适配器 α 处理。
字母解释:
α :adaptor适配器
$conv$:1x1卷积层
$bn$:批量归一化函数(batch normalization)
$γ()$:RELU激活函数
在这个过程中减少了通道数以降低冗余。
然后,我们采用类似unet的解码器来融合适应后的多尺度特征。对于每个级别的特征 fi,我们将其与解码器块中的较低级别特征 fi+1 融合,其中 di 是解码器中的第 i 层特征。然后我们将得到的特征${d1, d2, d3}$ 连接起来以获得适应 RS 域的语义表示。表示为:
Task-agnostic semantic learning(任务无关的语义学习)
文献表明,多个相关任务的联合学习可以提高每个单个任务的性能。为了提高 CD 的性能,我们引入了一个额外的时间语义学习分支。即对多时相 RSI 进行分类后进行变化分割。对于上文改编后的 SAM 特征 ${d1, d2, d3}$。我们进一步使用卷积运算将它们转换为候选潜在变量$\widehat{l}$ ∈ $R^{k×w×h}$,其中 k 表示 RSI 中感兴趣的语义簇的数量。
每个$f$表示一个卷积融合操作。
我们使用底层的时间约束来监督潜在语义的学习。与明确监督 LCLU 类别学习的文献研究不同,在二进制 CD 任务中,每个采集日期的语义标签不可靠。因此,SAM-CD 通过对齐特征表示来隐式监督双时态潜在变量的学习。对于每个候选潜在变量$\widehat{l}$,使用 softmax 函数对它们进行归一化:
其中T是控制输出特征概率分布的温度参数。我们设置 T > 1 以获得更多样化的语义表示。令 ${l1, l2}$为归一化双时态潜在变量,我们期望它们的语义表示在未更改的区域中相似。因此,我们提出时间约束损失$L_t$来衡量它们的时间相似性,计算如下:
其中,c是真实值GT的变体,将未变化的区域注释为 1。这是为了从损失计算中排除更改的区域。进一步利用注意力操作将语义焦点嵌入到变化特征 fc 中,然后将它们映射到变化映射 m 中。通过将 SAM 特征 $d1,d2,d3$ 传入到卷积块中来获得变化特征。注意力嵌入操作如下:
其中⊕是通道级联操作,σ是sigmoid归一化函数,conv1和conv2是两个用于调整特征通道的卷积模块。这确保了 CD 结果是语义感知的,从而更好地分割语义变化。
训练细节:
SAM-CD仅利用FastSAM的视觉编码器并丢弃提示解码器。在与任务无关的语义学习分支中,语义嵌入块是单个 1×1 卷积层。考虑到典型 CD 应用中通常很少有有趣的 LCLU 类,语义通道数 k 根据经验设置为 8。在变化检测分支中,我们按照文献中的实践,利用 6 层残差卷积块来构建变化嵌入模块。这是为了更好地将语义特征转化为变化表示。




