
Norm_Softmax_VIT笔记
一些术语
batch:批次,一批处理,
batch_size:表示每个batch有多少样本
LR(learning rate):学习率
patch:补丁
epoch:周期,阶段
criterion:评判准则(一般用于命名损失函数)
optimizer:优化器
BP:反向传播算法(Back Propagation),
通过计算误差的反向传播来更新网络的权重和偏置
Embedding:
是指将高维的离散型数据(如词汇、用户ID等)转换为低维的连续型向量的过程,也可以指转换后的向量
感受野(Receptive Field):
指在神经网络中,输出特征映射上的一个像素点对应在输入图像中的区域。感受野的大小取决于网络的架构和层数,它可以用来衡量网络对输入信息的感知范围和理解能力。
具体来说,感受野的大小在卷积神经网络(Convolutional Neural Network, CNN)中是递增的,随着网络层数的增加,感受野的大小也随之增加。在前面的卷积层中,每个像素点的感受野通常只是输入图像的一个小区域,但是在后面的卷积层中,每个像素点的感受野可以覆盖整个输入图像。这样,网络就可以学习到更全局的特征和上下文信息,以更好地理解输入图像并提高分类或检测的准确性。
感受野的大小与卷积核的大小、步幅和填充有关。通常,较大的卷积核、较小的步幅和合适的填充可以增加感受野的大小。此外,池化层(Pooling Layer)也可以增加感受野大小,它通过池化操作对输入特征映射进行缩小,从而扩大感受野范围。
在神经网络设计中,理解和控制感受野大小可以帮助我们更好地设计网络结构和优化算法,从而提高网络的性能和稳定性。
MLP(Multilayer Perceptron,多层感知器)
是一种基于前馈神经网络(Feedforward Neural Network)的模型,通常用于处理分类和回归问题。它由多个节点(神经元)组成,每个节点与前一层的所有节点相连。每个神经元的输出值是由前一层的神经元输出值通过权重参数的线性组合和激活函数的非线性变换计算得到的。MLP通常包含一个或多个隐藏层,以及一个输出层。也成为全连接神经网络(Fully Connected Neural Network)
BN Details
- Batch Normalization(BN)(批量归一化)是一种常用的神经网络正则化技术,旨在解决深度神经网络训练过程中的梯度消失和梯度爆炸问题,并改善网络性能和收敛速度。
- 为什么?
每一层参数更新,会导致输入分布差距 - 是什么?
小批量数据计算均值方差,处理归一 - 怎么做?
B={x1,x2,…xn}
计算出该小批量数据的均值与方差,归一化乘系数加偏置是为了输入不是集中在-1,1,在通过激活函数后非线性.优缺点:
BN的基本思想是将神经网络中每个隐藏层的输入标准化,以使其均值为0,方差为1。具体来说,BN在每个训练批次中计算出批次输入的均值和方差,然后将其应用于批次中的每个样本。标准化后的样本通过调整缩放因子和偏移因子来恢复其原始输入特征空间,这些因子通过学习得到。这样,即使网络的输入和参数分布发生变化,BN也可以保持网络的稳定性。
BN的主要优点是可以提高网络的收敛速度和泛化能力,并具有一定的正则化作用,可以减少过拟合的风险。此外,BN可以减少对学习率和其他超参数的依赖,提高网络的可训练性和可调节性。
BN的一些缺点包括增加了网络的计算复杂性和内存使用,特别是在大型网络和GPU计算上。此外,BN对小批量数据的表现可能很差,因为它需要计算均值和方差的无偏估计,必须依赖于有效的批量大小。
总之,BN是一种强大的神经网络正则化技术,可以改善网络性能和训练过程的稳定性,特别是在深度神经网络和大型数据集上。
Layer Norm
Layer Norm(层标准化)是深度学习中一种常用的归一化方法,用于减小模型中许多常见问题,如梯度消失(vanishing gradients)和梯度爆炸(exploding gradients)等。它是对Batch Norm的一种改进,解决了Batch Norm难以应用于序列模型和小批量数据的问题。
Layer Norm对于每个样本的每个特征分别进行归一化,使得每个样本在每个特征上都具有相似的分布,从而提高了模型的泛化性能。在Layer Norm中,对于每个样本的第i个特征,其标准化后的值为:
其中,均值和方差是在特征维度上计算的,epsilon是一个很小的常量,用于防止除以0
区别
- Layer Norm与Batch Norm的区别在于,Layer Norm是对每一层的输出进行标准化处理,而Batch Norm是对每一个batch进行标准化处理。
Softmax Details
softmax是一种用于多分类问题的激活函数,主要用于将一个向量转换为概率分布。在深度学习中,softmax通常用于输出层,将神经元的输出转换为类别概率。softmax函数的实现原理如下:
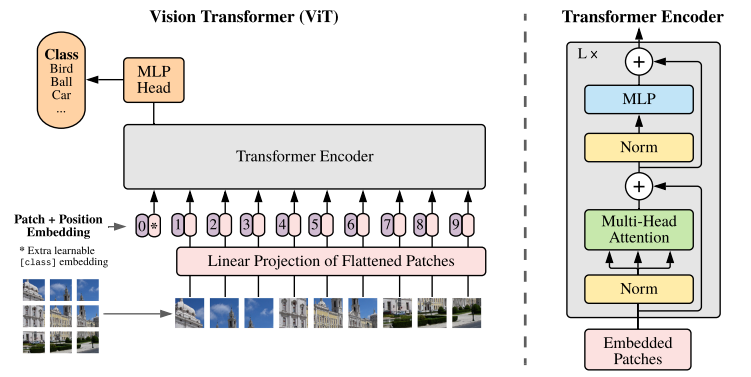
图像的处理:将输入图像分割成多个小图像(patch)。
patch的线性变换:对于每个patch,使用一个线性变换将其转换为一个向量(patch_embesdding)
位置编码:为每个patch添加位置编码,以表示它们在原始图像中的位置(posttion_embedding)(与patch_embedding的形状完全一样)
输入嵌入:将所有patch的向量和位置编码拼接(相加)在一起,形成一个输入嵌入(input embedding)矩阵。
Layer Norm
Transformer Encoder:对输入嵌入进行多层Transformer编码器的处理,以便进行全局的特征提取。这里使用Multi-Head Attention方法,具体步骤如下:
特征线性变换:每个输入序列复制3份(Q,K,V),经过线性变换,即将输入序列转换为多个查询(query)、键(key)和值(value)向量。
计算注意力分数:对于每个查询向量,计算它与所有键向量的内积,得到注意力分数的一组向量。
归一化:对注意力分数进行softmax归一化,得到所有键的权重分布。
加权求值:将所有值向量按照权重分布加权求和,得到该查询向量的注意力表示:引入wq,wk,wv权重,得到新的Q,K,V
多头注意力(Multi-Head):将上述步骤在多个子空间中分别进行,得到不同子空间的注意力表示。即:wq,wk,wv权重矩阵有H组,计算注意力分数的操作可以进行H次。
输出合并:将各子空间的注意力(H次Multi-Head运算的结果)表示拼接成一个向量。使用softmax进行处理。
线性变换:将合并后的向量再进行一次线性变换,得到最终输出。
Norm
(全局池化):对于输出矩阵中的所有特征向量,进行全局池化(如平均池化或最大池化)得到一个全局特征向量。
全连接层:将全局特征向量输入到一个全连接层,进行分类预测。为了实现每个像素之间的交互。
附:师兄笔记





